Apache Iceberg Architecture
Apache Iceberg is designed with a layered architecture to efficiently manage large analytic datasets, support schema evolution, and enable features like time travel and concurrent writes.
Layers Overview
Iceberg consists of three main layers:
- Catalog Layer – Manages table locations and metadata pointers.
- Metadata Layer – Tracks table metadata, schema, partitioning, and file statistics.
- Data Layer – Stores the actual table data and delete information.
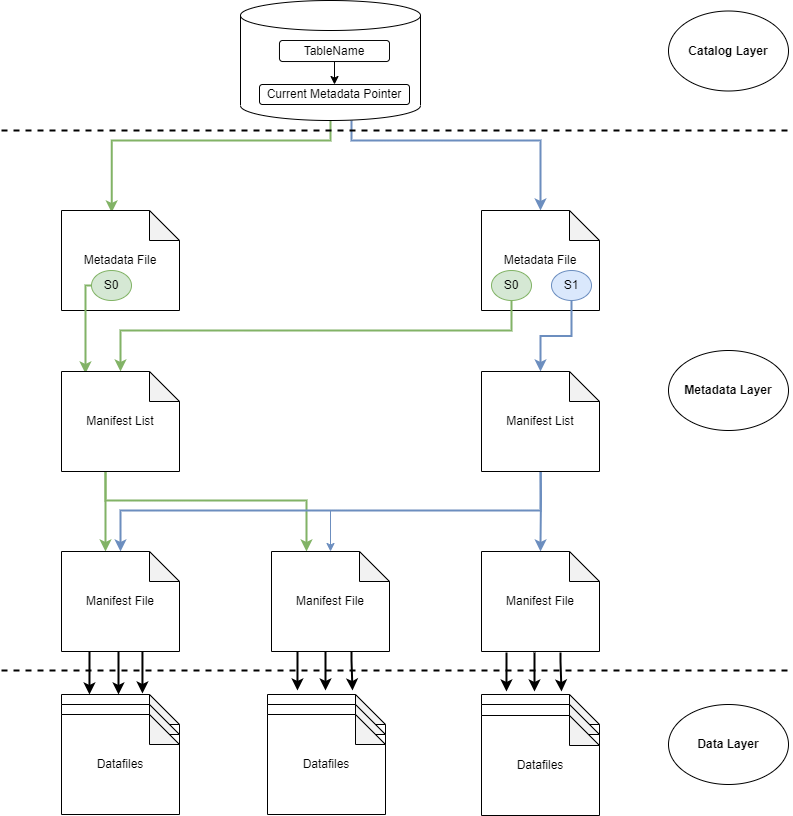
Catalog Layer
The catalog layer maps fully qualified table names (namespace + table) to their current metadata file (metadata pointer). It ensures atomic updates to the metadata pointer, so all readers and writers see a consistent table state.
Depending on the catalog implementation, the metadata pointer is stored differently:
- S3: Uses a file named
version-hint.textin the table’s metadata folder, containing the current metadata file version. - AWS Glue: Stores the pointer as a table property called
metadata_location, holding the full path to the current metadata file. - Apache Hive: Uses the
locationtable property to point to the current metadata file.
Metadata Layer
The metadata layer contains all metadata files for an Iceberg table. It forms a tree structure that tracks data files, delete files, and the operations that created them. This layer is essential for efficient data management and enables features like time travel and schema evolution.
Three key file types:
Manifest File
Manifest files track data files and delete files, along with statistics such as minimum and maximum column values. These files are generated incrementally during writes, making statistics collection efficient compared to legacy formats like Hive.
- Separate manifest files track data files and delete files, but both use the same schema.
- Manifest files store statistics at write time, avoiding expensive full-table scans required by older formats.
- Query engines use manifest file statistics (e.g., upper/lower bounds, null counts, partition data) for file pruning, improving query performance.
Manifest List
A manifest list captures the state of an Iceberg table at a specific point in time. It contains a list of manifest files, each describing:
- Data file locations
- Partition information
- Upper and lower bounds of partition columns
Query engines use manifest lists to evaluate partition specs and skip irrelevant files, enabling fast, efficient reads.
Metadata File
The metadata file tracks manifest lists and contains the table’s schema, partitioning details, snapshots, and the identifier of the current snapshot. Each table modification creates a new metadata file, registered as the latest version.
This design supports:
- Concurrent writes: Multiple engines can write data simultaneously without conflict.
- Consistent reads: Readers always access the latest committed version of the table.
Data Layer
The data layer holds the actual table data, consisting of data files and delete files. It is typically backed by distributed storage systems such as HDFS, Amazon S3, Google Cloud Storage (GCS), Azure Data Lake Storage (ADLS), and others.
- Data Files: Store the actual table data. Supported formats include Apache Parquet, Apache Avro, and Apache ORC.
- Delete Files: Track rows deleted from the dataset without rewriting underlying data files, enabling efficient deletes.
Data in a data lake should be immutable. Updates are handled by writing new files rather than modifying existing ones.
Data Modification Approaches
Apache Iceberg supports two approaches for handling data changes:
- Copy-On-Write (COW): Changes are applied by creating a new version of the data file with updates. The old file is replaced.
- Merge-On-Read (MOR): Changes (inserts, updates, deletes) are written to separate delta or delete files. Query engines merge these changes with base data at read time.
Supported Delete Operations
- MOR delete methods
- Positional delete files
- Equality delete files
Iceberg’s layered architecture enables scalable, reliable, and flexible data lake management, supporting advanced analytics and evolving business requirements.